Understanding Deep Learning Approaches for Object Detection and Classification: R-CNN and YOLO
Deep Learning is a rapidly evolving research and development topic spanning an ever-increasing number of applications fields from remote sensing to autonomous driving. The rise in the activities in deep learning started around mid-way between 2010 and 2020 and trend still continues to this date. Deep learning has made previously difficult recognition and classification tasks much more efficient and accurate.
Although decision trees, support vector machines (SVM), random forests and gradient boosting methods have been successfully applied to solve remote sensing problems, deep learning methods are the next technology and actually the state-of-the-art.
Deep learning methods developed quickly in computer vision and thus could be expected to work well with in remote sensing given the ever-increasing resolution of remote-sensed images. With the use of high-resolution satellite Imagery (~1- 4 m/pixel) or UAV/drone images, arbitrary resolution can be achieved thus opening up previously unthinkable computer vision algorithms to remote sensing.
Here we pick up some of the algorithms and provide a quick overview of some of the popular and exciting features of deep learning methods that can be explored to enhance classification results. By far the Convolutional Neural Networks (CNN) have been found to efficient and effective for image recognition and classification tasks. CNN-based approaches would be the best starting point for remote sensing applications as well.
Region-Based Convolutional Neural Networks (R-CNN)
The Region-Based Convolutional Neural Networks (R-CNN), are a family of CNN models intended for use in solving object detection problems and originally developed by Ross Girshick, et al. There are four commonly used models summarized as follows:
R-CNN (Ross Girshick et al.: https://arxiv.org/abs/1311.2524 )
This is base of the other methods and consist of first applying selective search to extract up to 2000 bounding boxes (or regions) per image followed by feature extraction using CNN. A support vector machine (SVM) is then used to classify the features and finally adjustment of the bounding boxes is done by regression.
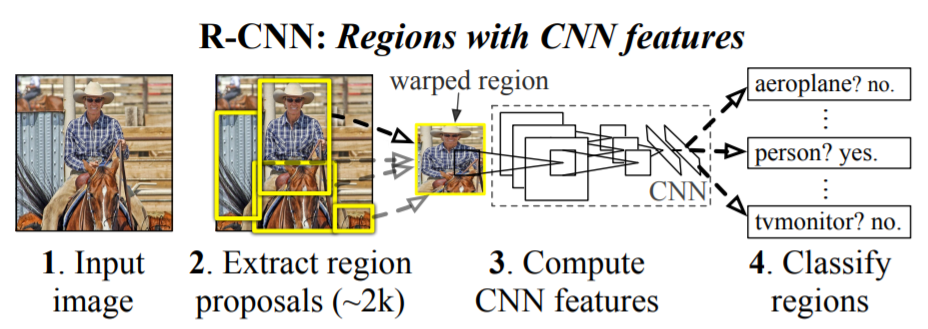
Source: https://arxiv.org/abs/1311.2524
R-CNN Problems:
- High computational processing due to the large amounts of regions fed into CNN after the first step.
- Huge amount of space is required for generation of bounding boxes.
Fast R-CNN (Ross Girshick: https://arxiv.org/abs/1504.08083 )
To speed up the R-CNN the input image is fed to the CNN only once per image in order to generate a convolutional feature map. Additionally, a softmax layer is used to predict the class of the proposed region and also the offset values for the bounding box.
Selective search is still performed but only projection to mapping CNN-generated feature map is done instead of running a full CNN for every region proposal.
Faster R-CNN (Shaoqing Ren et al.: https://arxiv.org/abs/1506.01497 )
This variation of R-CCN eliminates the time-consuming selective search found in both R-CNN and Fast R-CNN and directly uses the region proposals region proposals for learning. The speed up is about 10x compared to Fast R-CNN and almost 100x compared to R-CNN.
Mask R-CNN (Kaiming He et al.: https://arxiv.org/abs/1703.06870 )
Mask R-CNN builds on Faster R-CNN by adding pixel-level segmentation of the objects instead of just bounding boxes. This is achieved by using a binary mask hence the name Mask R-CNN. An additional region alignment processing was also utilized to improve pixel-level segmentation. The accuracy of the resulting method superior to all the above methods and is wonderful, to say the least.

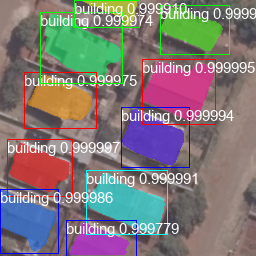
Building footprint detection by Mask R-CNN (Left: Input, Right: Detection Result)
YOLO (You Look Only Once)
YOLO (Joseph Redmon, et al.: https://arxiv.org/abs/1506.02640 ) takes a different approach from R-CNN methods. As opposed to the R-CCN methods described above, YOLO the takes the whole image as input and uses a single convolutional neural network to simultaneously predicts the bounding boxes and the class probabilities for these boxes by t formulating object detection as a regression problem. The result is a high algorithm that can be used in realtime processing (>30 fps).
The processing starts by dividing the image into a grid of S x S and each grid predicts M bounding boxes and their associated confidence scores. The confidence reflects the level of confidence that the model has that bounding box contains the objects of interest and accuracy of the box prediction itself. It is defined as a product of the probability of the object and intersection over union (IOU) between the predicted box and the ground truth.
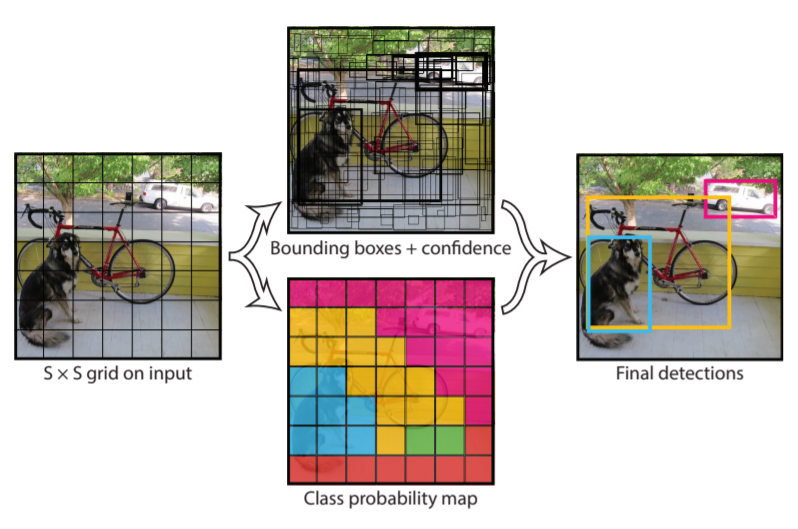
Source: https://arxiv.org/abs/1506.02640
The price to pay for speed is the constraints imposed by bounding boxes making it difficult generalize the algorithm and, in some cases, to recognize small objects.
Conclusion
Deep learning is an evolving subject and we just up presented a sample of concepts involved in some methods in use. In the context of remote sensing, CNNs are slowly beginning to find their way into classification tasks. One example is the use of Mask R-CNN very accurate building footprint detection. We hope you found this information useful and that it motivates you to jump onto bigger and more advanced topics. We will continuously update this content do remember to come back!
Please don’t hesitate to contact us for any enquires. We will get back to you fast!
Get recent trends on technology from our books and paper publications. These materials present an exciting perspective into innovative technologies that will shape the future.
Highlighted Papers
Simulating Urban Growth Using a Random Forest-Cellular Automata (RF-CA) Model
Recommended Books
Remote Sensing Image Classification in R

Radar Signal Processing for Autonomous Driving
